
Interpretability-Aware Pruning for Efficient Medical Image Analysis
An attribution-guided pruning method for medical AI that preserves accuracy and interpretability


Paper link: https://arxiv.org/abs/2507.08330
Listen to the Author Insights
Explore the research through an in-depth conversation between the authors — Vinay Kumar Sankarapu (Founder & CEO), Pratinav Seth (Research Scientist), and Nikita Malik (AI Intern) from AryaXAI.
Gain behind-the-scenes perspectives on the motivation, methodology, and practical impact of their work on interpretability-aware pruning for medical AI.
Abstract
As deep learning continues to push the boundaries of performance in medical imaging, a fundamental tension remains: large models deliver high accuracy, but they are hard to deploy and difficult to trust. This paper, presented by AryaXAI Alignment Lab and Manipal Institute of Technology, introduces an innovative solution—interpretability-aware pruning—to compress deep models without sacrificing their performance or transparency.
The work presents an interpretability-guided pruning framework that reduces model complexity while preserving accuracy and transparency. By retaining only the most relevant parts of each layer, the method enables targeted compression that maintains clinically meaningful features. Experiments on multiple medical image classification benchmarks show that it achieves high compression rates with minimal accuracy loss, making it ideal for real-world healthcare deployment.
1. Introduction
Modern medical imaging models, especially deep convolutional neural networks (CNNs) and transformers, have achieved state-of-the-art results in tasks like disease detection, image classification, and diagnosis. However, their adoption in real-world clinical environments is limited due to:
- Computational complexity: These models are often too large for edge deployment.
- Lack of transparency owing to their "black-box" nature: Clinicians need to understand why a model makes a decision.
To tackle the challenges of deploying large, opaque neural networks in clinical settings, this paper proposes a novel interpretability-aware pruning method. While traditional pruning techniques reduce model size by removing parameters based on heuristics like weight magnitude or random selection, they often overlook the role those parameters play in the model’s decision-making. This can harm performance or transparency.
Instead, the authors leverage advanced interpretability techniques—Layer-wise Relevance Propagation (LRP), DL-Backtrace (DLB), and Integrated Gradients (IG)—to compute importance scores for individual neurons and layers. These scores guide a more informed pruning process, helping to eliminate only the less relevant parts of the network. The result: significant model compression without sacrificing accuracy or interpretability, demonstrated effectively across multiple medical imaging tasks.
2. Related Works
2.1 Model Pruning
Model pruning reduces the size of neural networks by eliminating less important weights or neurons. Two common strategies:
- Train-time pruning: Prunes during training.
- Post-training pruning: Prunes a pre-trained model. This is the approach used in the paper.
Traditional pruning methods often use weight magnitude or random removal but lack a connection to the model's decision-making.
2.2 Model Interpretability and Model Compression
Interpretability aims to explain a model’s internal workings. In high-stakes domains like healthcare, explainability is not optional—it’s essential. The intersection of interpretability and compression has led to strategies like "pruning by explaining," where only the less-relevant parts of the network are removed.
Attribution Methods Used:
- Layer-wise Relevance Propagation (LRP): Tracks neuron importance via a conservation principle that distributes "relevance" backward through the network.
- DL-Backtrace (DLB): A model-agnostic technique that reveals information flow and feature importance without relying on baselines. A significant advantage of DLB is its
- independence from auxiliary models or baselines, ensuring consistent and deterministic interpretations across diverse architectures (MLPs, CNNs, LLMs) and data types (images, text, tabular data).
- Integrated Gradients (IG): Computes the integral of gradients from a baseline to the input, offering an axiomatic view of feature contribution.
3. Methodology
The proposed interpretability-aware pruning method combines interpretability techniques with a targeted strategy for removing neurons. It follows a structured process: compute importance scores for each neuron using attribution methods, then iteratively prune the least important ones. This approach enables efficient model compression while maintaining transparency and performance.
3.1 Importance Score Computation
The method begins by quantifying the importance of individual neurons using three attribution techniques: LRP, DLB, and IG. These methods generate relevance scores across different feature levels, which are then aggregated across channels to compute a stable, per-neuron importance score. This aggregation reduces noise and offers a clearer measure of each neuron's contribution to the model’s predictions.
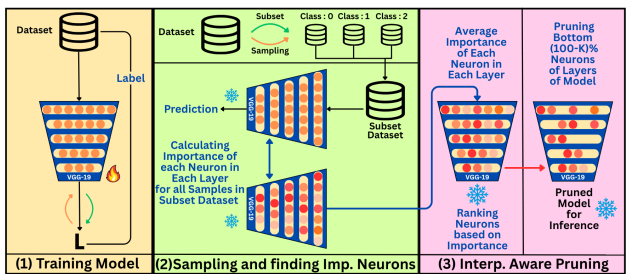
3.2 Sample Selection for Importance Computation
Since relevance can vary by input, the authors use 10 samples per class to calculate scores, using three sampling strategies:
- Confidence Sampling: Selects high-confidence predictions.
- Random Sampling: Selects samples randomly from each class.
- Clustering-Based Sampling: Uses feature-space clustering to pick representative samples, ensuring diversity.
3.3 Pruning Strategy
Neurons are ranked based on their aggregated importance. A predefined pruning threshold (e.g., bottom 30%) determines which neurons to prune. Pruned neurons have their weights zeroed out, effectively removing them. This results in unstructured neuron pruning, but with the critical advantage of interpretability-driven selection.
4. Experimental Setup
4.1 Datasets and Models
The study evaluated the pruning method on four diverse medical imaging datasets:
- MURA: X-rays of bones (e.g., wrist, shoulder), labeled as normal or abnormal.
- KVASIR: Endoscopic images of the GI tract, categorized by anatomical and pathological features.
- CPN: Focused on diagnosing common peroneal nerve injuries in the lower limb.
- Fetal Planes: High-resolution ultrasound images of fetal brain regions, used for classification and detection.
Three architectures were evaluated:
- VGG19
- ResNet50
- Vision Transformer (ViT-B/16)
Each model was trained from scratch using standard augmentation, learning rate scheduling, and Cross Entropy loss to establish strong performance baselines before pruning.
4.2 Pruning Process and Evaluation
For each model and dataset, neuron importance scores were calculated using the sampling techniques. Neurons with the lowest scores were pruned based on thresholds (15%, 30%, 50%, 70%). The models were then evaluated for both accuracy and efficiency, with particular focus on identifying the point of lossless pruning, where significant compression is achieved without compromising model performance.
5. Results and Discussion
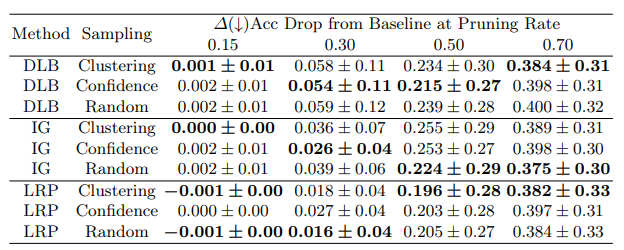
The results confirm that the proposed interpretability-guided pruning method is effective across various medical imaging datasets and model architectures. Using attribution methods like LRP, DLB, and IG, the approach consistently achieves high compression rates while maintaining model accuracy—typically within a 5% drop, even at moderate pruning levels. The findings also underscore the influence of pruning strategies, attribution techniques, and sampling methods on model resilience under compression.
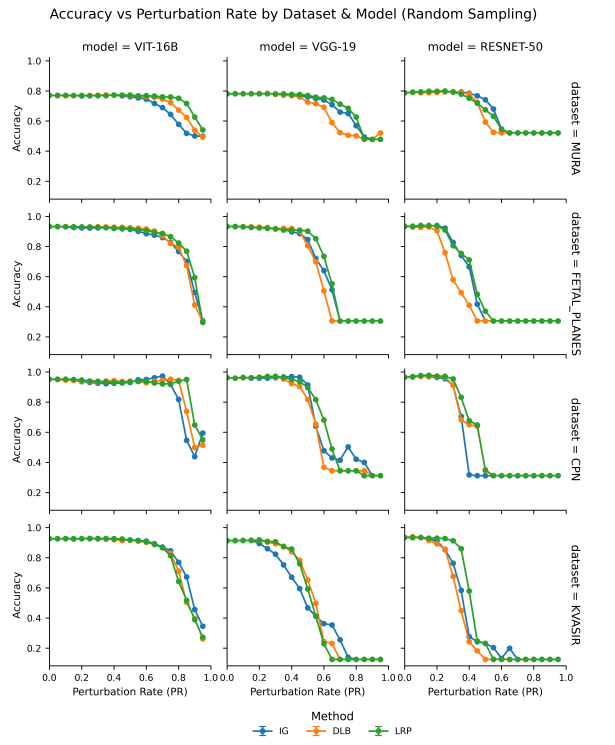
5.1 Model-Wise Observations
Across all datasets, Vision Transformers (ViTs) showed the highest accuracy and strongest robustness to pruning, maintaining performance even after 65–85% of neurons were removed—especially when paired with LRP or DLB. This suggests ViTs have greater redundancy or feature richness compared to CNNs. VGG models handled pruning up to 45–55% with minimal accuracy loss, while ResNets were more sensitive, typically tolerating only 25–35% pruning. These differences reflect architectural traits, with ResNet’s residual connections potentially making unstructured pruning less effective.
5.2 Impact of Different Interpretability Methods
- LRP consistently delivered the best pruning results, preserving accuracy at higher compression levels.
- DLB and IG followed closely, but were slightly less robust than LRP.
5.3 Impact of Different Sampling Strategies
- Clustering outperformed other sampling strategies, especially at moderate pruning rates (30–50%).
- Confidence-based sampling sometimes surpassed random selection, particularly in IG and DLB.
- Random sampling was surprisingly effective for ViTs—possibly due to the transformer’s representational richness.
Interestingly, at lower pruning rates (15–30%), accuracy occasionally improved post-pruning. This suggests that pruning noisy or redundant neurons can enhance generalization.
6. Implications for Medical Image Analysis
Interpretability-aware pruning brings key advantages to healthcare AI systems:
- Efficiency: Enables 40–50% lossless pruning, producing lightweight models suitable for edge devices and resource-limited clinical settings, while accelerating diagnostics.
- Interpretability: Makes compression transparent by retaining neurons most critical to decision-making, helping clinicians understand model behavior.
- Robustness: Diverse sampling ensures important neurons for varied or edge-case inputs are preserved, boosting model reliability.
7. Conclusion
This work presents a novel interpretability-aware pruning framework that uses attribution-based importance scores—rather than traditional heuristics—to guide the compression of deep neural networks for medical image analysis. Evaluated across four datasets (MURA, CPN, KVASIR, and Fetal Planes) and three model architectures (VGG19, ResNet50, and ViT-B/16), the method achieved high pruning rates (up to 80–85%) with minimal loss in accuracy.
ViT models showed strong resilience under compression, making them ideal for resource-constrained clinical settings. Among the interpretability techniques, Layer-wise Relevance Propagation (LRP) enabled the most effective pruning, followed by DL-Backtrace (DLB) and Integrated Gradients (IG). Additionally, clustering-based sampling outperformed other strategies, leading to more robust pruning outcomes.
In some cases, pruning even improved model accuracy by removing noisy or redundant neurons, enhancing generalization. These findings underscore the dual benefit of the method—efficient compression and improved interpretability—making it a powerful approach for deploying trustworthy AI in healthcare.
References
1. Geert Litjens, Thijs Kooi, Babak Ehteshami Bejnordi, Arnaud Arindra Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen AWM van der Laak, Bram van Ginneken, and Clara I Sánchez. A survey on deep learning in medical image analysis. Medical image analysis, 42:60–88, 2017.
2. Dinggang Shen, Guorong Wu, and Heung-Il Suk. Deep learning in medical image analysis. Annual Review of Biomedical Engineering, 19:221–248, 2017.
3. Andre Esteva, Kevin Chou, Serena Yeung, Nikhil Naik, Ali Madani, Avan Mottaghi, Yun Liu, Eric Topol, Jeff Dean, and Richard Socher. Deep learning-enabled medical computer vision. npj Digital Medicine,
4(1):5, 2021. 4. Andreas Holzinger, Chris Biemann, Constantinos S Pattichis, and Douglas B Kell. What do we need to build explainable ai systems for the medical domain? arXiv preprint arXiv:1712.09923, 2017.
5. Davis Blalock, Jose Javier Gonzalez Ortiz, Jonathan Frankle, and John V Guttag. What is the state of neural network pruning? Proceedings of Machine Learning and Systems, 2:129–146, 2020.
6. Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. International Conference on Learning Representations (ICLR), 2019.
7. Song Han, Jeff Pool, John Tran, and William J. Dally. Learning both weights and connections for efficient neural networks. In Advances in Neural Information Processing Systems (NeurIPS), 2015.
8. Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations (ICLR), 2019.
9. Trevor Gale, Erich Elsen, and Sara Hooker. The state of sparsity in deep neural networks. arXiv preprint arXiv:1902.09574, 2019.
10. Grégoire Montavon, Sebastian Lapuschkin, Alexander Binder, Wojciech Samek, and Klaus-Robert Müller. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognition, 65:211–222, 2017.
11. Vinay Kumar Sankarapu, Chintan Chitroda, Yashwardhan Rathore, Neeraj Kumar Singh, and Pratinav Seth. Dlbacktrace: A model agnostic explainability for any deep learning models, 2025.
12. Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 3319–3328. PMLR, 2017.
13. Michael Zhu and Suyog Gupta. To prune, or not to prune: exploring the efficacy of pruning for model compression. In International Conference on Learning Representations (ICLR), 2018.
14. Victor Sanh, Thomas Wolf, and Alexander M Rush. Movement pruning: Adaptive sparsity by fine-tuning. In Advances in Neural Information Processing Systems, volume 33, pages 20378–20389, 2020.
15. Babak Hassibi and David G Stork. Second order derivatives for network pruning: Optimal brain surgeon. In Advances in Neural Information Processing Systems (NeurIPS), pages 164–171, 1993.
16. Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Reduan Achtibat, Thomas Wiegand, Wojciech Samek, and Sebastian Lapuschkin. Pruning by explaining revisited: Optimizing attribution methods to prune cnns and transformers, 2024.
17. Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, Raja Chatila, and Francisco Herrera. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai, 2019.
18. Prashant Gohel, Priyanka Singh, and Manoranjan Mohanty. Explainable ai: current status and future directions, 2021.
19. Shahin Atakishiyev, Mohammad Salameh, and Randy Goebel. Safety implications of explainable artificial intelligence in end-to-end autonomous driving, 2025.
20. Benjamin Fresz, Vincent Philipp Göbels, Safa Omri, Danilo Brajovic, Andreas Aichele, Janika Kutz, Jens Neuhüttler, and Marco F. Huber. The contribution of xai for the safe development and certification of ai: An expert-based analysis, 2024.
21. Muhammad Sabih, Frank Hannig, and Juergen Teich. Utilizing explainable ai for quantization and pruning of deep neural networks. ArXiv, abs/2008.09072, 2020.
22. Grégoire Montavon, Alexander Binder, Sebastian Lapuschkin, Wojciech Samek, and Klaus Müller. Layer-wise relevance propagation: An overview. In Explainable AI, 2019.
23. Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning, 2017.
24. Pranav Rajpurkar, Jeremy Irvin, Kaylie Zhu, Brandon Yang, Hershel Mehta, Tony Duan, Daisy Ding, Aarti Bagul, Curtis Langlotz, Katie Shpanskaya, Matthew Lungren, and Andrew Ng. Mura: Large dataset for abnormality detection in musculoskeletal radiographs. arXiv preprint arXiv:1712.06957, 2017.
25. Konstantin Pogorelov, Morten Eskeland, Kjersti Sigrunn Tveit, Thomas de Lange, Dag Johansen, Håvard Espeland, Casper G Heslinga, Catalin Gori, Sigrun Losada Eskeland, Michael Riegler, et al. Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection. In Proceedings of the 8th ACM on Multimedia Systems Conference, pages 164–169, 2017.
26. Sachin Kumar. Covid19-Pneumonia-normal chest X-Ray images, 2022.
27. Xavier P Burgos-Artizzu, David Coronado-Gutiérrez, Brenda Valenzuela-Alcaraz, Elisenda Bonet-Carne, Elisenda Eixarch, Fatima Crispi, and Eduard Gratacós. Evaluation of deep convolutional neural networks for automatic classification of common maternal fetal ultrasound planes. Sci. Rep., 10(1):10200, June 2020.
28. Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
29. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
30. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021.
Related Research Papers


See how AryaXAI improves
ML Observability
Learn how to bring transparency & suitability to your AI Solutions, Explore relevant use cases for your team, and Get pricing information for XAI products.









.png)





