

Refining LLM Behavior with Natural Language Feedback: A Scalable Prompt Learning Strategy
9 minutes
July 31, 2025

In the fast-evolving landscape of large language model optimization, the path to performance often lies in the subtleties of user intent and LLM alignment. While traditional fine-tuning and reinforcement learning with human feedback (RLHF) have long served as foundational strategies, a newer paradigm is emerging: prompt learning powered by natural language feedback. This approach offers a lightweight, interpretable, and scalable method to iteratively guide LLM behavior tuning without retraining underlying weights.
In this blog, we explore how prompt learning compares with conventional techniques like fine-tuning vs prompt engineering, and why it holds significant promise for developers and enterprises deploying LLMs in production.
From Model Weights to Prompts: A Shift in Optimization Philosophy
Early LLM development focused on internal model changes via full fine-tuning or RLHF—both computationally expensive and difficult to interpret. As models moved into real-world, high-stakes applications, the need for faster, more transparent control led to prompt-based tuning.
Prompt engineering emerged as a more agile alternative. By modifying prompts—e.g., “respond in a formal tone”—teams can experiment rapidly and guide behavior without retraining. This approach enables a new level of LLM interpretability, especially in domains like healthcare, legal, and finance.
More importantly, it signals a philosophical transition: from internal model rewiring to external steering through instruction-tuned LLMs—aligning with how humans learn via language and feedback.
Why English-Language Feedback?
In optimizing large language models (LLMs), one powerful yet underutilized tool is natural human language—especially English-language feedback. Instead of relying solely on structured data or ratings, developers can guide model behavior with simple, intuitive prompts like “be more concise” or “eliminate passive voice.” This kind of feedback bridges human expectations and machine outputs in a more direct, flexible, and accessible way.
1. Reduces Reliance on Labeled Data
Traditional fine-tuning methods require large, annotated datasets for every behavioral tweak. In contrast, natural language feedback allows developers to convey preferred behaviors with a single instruction, eliminating the need for thousands of labeled examples.
2. Enhances Interpretability and Control
Prompt-based feedback is transparent and easy to reason about. Unlike model weight adjustments, which often obscure cause and effect, prompt changes are readable and versionable—ideal for environments that require trust and accountability. Prompts also enable modular tuning; different behaviors can be tailored for different use cases without interfering with each other.
3. Speeds Up Iteration
Prompt updates can be deployed instantly—no retraining or model versioning required. This fast, flexible iteration cycle is especially critical for production systems and third-party APIs where internal model access isn’t available.
4. Enables Optimization in Black-Box Models
With proprietary LLMs, prompt engineering becomes the only viable means of control. English-language feedback lets teams steer behavior, tone, and accuracy—even in closed systems—making it not just useful, but essential.
How Prompt Learning Works with Natural Language Feedback
Prompt learning with natural language feedback is a structured, iterative method for refining large language model (LLM) behavior—without touching the model’s internal weights. Instead of relying on costly retraining, this approach centers around modifying the input prompts based on descriptive human feedback. The process involves four key stages:
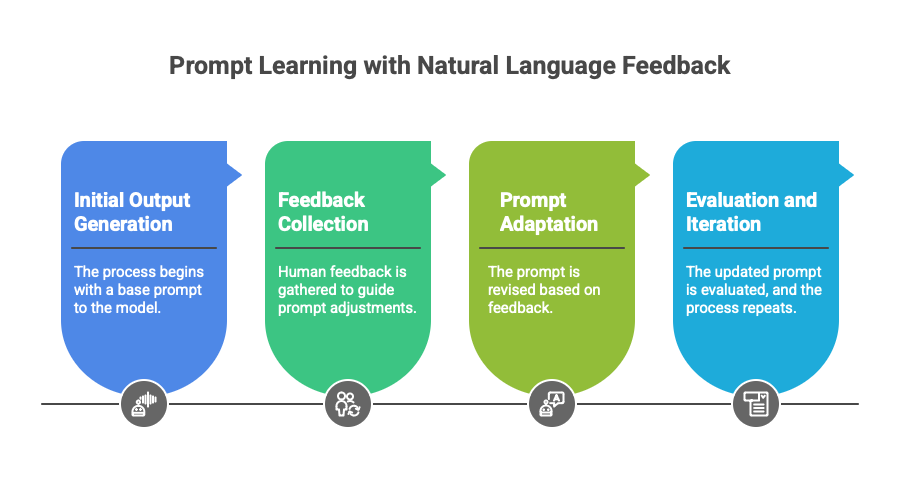
1. Initial Output Generation
The cycle begins with submitting a base prompt to the model. This prompt defines the task—for example, “Write a summary of this article for a general audience.” The model generates a response, which is used as the baseline for evaluation.
This step helps establish the model's unmodified behavior and highlights areas for improvement, such as unclear tone, verbosity, or misaligned structure.
2. Feedback Collection
Once the initial output is reviewed, human feedback is gathered. This feedback is written in plain English and typically provided by domain experts, reviewers, or end users. Importantly, it goes beyond binary ratings and includes specific suggestions, such as:
- “Too much jargon—simplify the language.”
- “Avoid repetition in the second paragraph.”
- “Use a more empathetic tone.”
This step translates subjective expectations into actionable input that can guide prompt adjustments.
3. Prompt Adaptation
The feedback is then incorporated into a revised prompt. This can include:
- Adding explicit instructions (e.g., “Use simple language suitable for high school readers.”)
- Rephrasing the task for clarity
- Providing context or examples to guide structure and tone
These edits steer the model’s output in a more desirable direction, without retraining or altering its internal logic.
4. Evaluation and Iteration
The updated prompt is submitted, and the model’s new response is evaluated against the original. Teams assess the improvements using criteria such as clarity, tone, relevance, or factual accuracy. The process can then be repeated, refining the prompt further based on new feedback.
This loop is particularly valuable for applications where behavior needs to adapt quickly to user expectations or compliance needs.
Supporting Tools and Infrastructure
To scale prompt learning effectively, organizations can leverage internal tools or third-party platforms that support:
- Side-by-side output comparisons for evaluating prompt impact
- Prompt versioning and audit trails to ensure traceability and control
- Feedback aggregation and clustering for actionable insights
- Human-in-the-loop workflows for continuous alignment with user expectations
These capabilities help teams iterate faster, maintain compliance, and adapt LLM behavior in dynamic enterprise environments—without needing access to underlying model weights.
Practical Applications Across Domains
Prompt optimization using natural language feedback is already delivering real-world impact across a range of industries. By embedding descriptive guidance directly into prompts, teams can steer model behavior with greater precision—without retraining or complex engineering. Here are some notable use cases:
Customer Support Automation
In customer service workflows, aligning tone and reducing hallucinated content is critical. Natural language feedback such as “respond in a calm and empathetic manner” or “only use information from the knowledge base” helps tailor the LLM’s responses to reflect brand guidelines and avoid misinformation. This leads to more consistent, trustworthy support interactions.
Healthcare Chatbots
Healthcare applications require strict adherence to both clinical accuracy and regulatory standards. Prompt modifications based on feedback like “include a disclaimer that this is not medical advice” or “structure the response using bullet points for clarity” ensure that outputs remain informative while meeting compliance requirements. It also helps reduce risk in sensitive patient-facing use cases.
Legal Document Drafting
In legal domains, precision and clarity are non-negotiable. Prompt-level adjustments based on feedback such as “use formal legal language” or “remove speculative or vague phrasing” help LLMs generate outputs that are more aligned with legal standards. This not only enhances draft quality but also reduces manual correction time for legal teams.
Human-Centered Alignment: A New Foundation
LLMs are adaptive, probabilistic systems. LLM alignment isn’t one-and-done—it must evolve. Natural language feedback supports continuous improvement based on human expectations.
This is especially useful in multi-stakeholder settings, where different teams require different outputs. For instance, legal may need formal, cautious language, while marketing seeks a friendly tone. Prompt-based learning enables these differences without retraining or duplicating models.
By prioritizing human input, prompt learning offers a flexible, scalable, and transparent way to align LLMs—one that adapts to real-world complexity without added technical burden.
Future Outlook: Toward PromptOps
As prompt learning becomes central to LLM optimization, there’s a growing need for structured practices—enter PromptOps. Similar to how MLOps standardized model operations, PromptOps brings order to prompt-based development by treating prompts as versioned, testable, and auditable assets.
PromptOps not only accelerates iteration but introduces auditability, version control, and policy enforcement—critical for regulated sectors like finance, healthcare, and public infrastructure.
Key elements of PromptOps include:
- Prompt version control to track, revert, and compare changes.
- Feedback-linked repositories for traceable prompt adjustments.
- A/B testing of prompt variations to optimize performance.
- Role-specific prompt libraries for tailored outputs across teams.
By operationalizing prompts, organizations can scale LLM use more effectively—especially in regulated or high-stakes settings. PromptOps ensures alignment with business goals, user needs, and compliance standards, while supporting rapid iteration and innovation.
Conclusion
Prompt learning powered by English-language feedback is more than a clever hack—it represents a paradigm shift in how we optimize and govern the behavior of large language models. It blends interpretability with scalability, enables faster iteration, and allows domain experts to stay in the loop without needing ML expertise.
As enterprises continue to adopt LLMs across domains, this approach will likely become a cornerstone of responsible and adaptive AI systems. The future of LLM optimization may not lie in weights, but in words.
SHARE THIS



Discover More Articles
Explore a curated collection of in-depth articles covering the latest advancements, insights, and trends in AI, MLOps, governance, and more. Stay informed with expert analyses, thought leadership, and actionable knowledge to drive innovation in your field.
.png)



Is Explainability critical for your AI solutions?
Schedule a demo with our team to understand how AryaXAI can make your mission-critical 'AI' acceptable and aligned with all your stakeholders.


AryaXAI provides the most accurate explainability and alignment stack to deliver accurate, true-to-model explainability, monitoring, risk management, and alignment techniques essential for highly mission-critical or regulated AI solutions.
Address: 3828 Kennett Pike, Suite 212 Greenville, DE 19807-2331
Products
Resources
Follow Us



Get in touch




