

Why Context Engineering is the future of LLMs
7 minutes
September 3, 2025

For many years, the magic of AI was an illusion that it was all in the prompt. We had documents about wizards that were able to come up with a few ideal words to reveal the maximum potential of a model. But as artificial intelligence evolves, real work is shifting behind the scenes. The age of prompt engineering is making way for a more central and important discipline: context engineering.
This post states that it's not so much about what you are asking, but what you provide the model to work with. It's between having a question in a vacuum and providing an excellent apprentice with a full, well-structured folder of everything they will need to excel. This is where the real reliability and potential of contemporary AI systems are being constructed.
In the fast-changing landscape of artificial intelligence, the attention is turning. Where we spent so much time worrying about creating the ideal prompt, now a new, broader skill has taken center stage: context engineering. It's the art and science of designing solid systems that give an LLM everything it needs to know, tools to use, and constraints to act within to accomplish something successfully. It's a matter of going from one-shot interactions to the creation of dynamic, intelligent agents.
What is Context Engineering?
Context engineering is all about putting an AI model in the best position to succeed by providing it with more than a prompt. Rather than relying on the right phrasing being the key to the best answer, you construct the context within which the model operates—giving it the proper data, tools, and rules so it can provide accurate and consistent responses. Imagine providing a clever but new hire with a complete briefing folder, the proper resources, and specific directions before inviting them to come up with a solution.
This extends far beyond a single question. A properly engineered context allows the AI to draw in pertinent information from previous conversations, retrieve facts from a database, apply outside tools such as a calculator or search engine, and adhere to tone or policy guidelines. By precisely controlling what the model gets to observe and how it processes, context engineering transforms AI from a smart guesser into a trustworthy collaborator that can manage real-world tasks.
Context Engineering is a System
One thoughtful question isn't a system. Context engineering is the end-to-end machinery that envelops an LLM so it can work reliably, repeatedly, and at scale. It draws information from various locations—the user's request, previous conversation, internal documents, databases, search tools, calendars, APIs—and integrates them into one coherent, well-organized package the model can act on.
Key building blocks
- Connectors & ingestion: Pull content from sources (knowledge bases, tickets, drive docs, APIs). Add metadata (owner, freshness, permissions).
- Normalization & enrichment: Clean, chunk, and embed text; label facts, constraints, and goals so the model can “see” structure.
- Retrieval & ranking: Use hybrid search (semantic + keyword + recency) to bring back only what matters; de-duplicate and weight by authority.
- Orchestration & planning: A controller manages the flow of tasks by determining which tools to call, what information to retrieve, when to summarize, and how to route complex workflows. This decision-making is policy-driven, meaning the controller follows explicit rules, constraints, and optimization strategies (e.g., cost, latency, accuracy, compliance) rather than relying solely on ad-hoc choices.
- Context packaging: Assemble inputs into clear sections (e.g., User Query, Facts, Policies, Examples, Tools). Budget tokens, compress long content, include citations.
- Action layer (tools): Calculators, search, policy checkers, CRM/DB updaters—invoked with strict schemas and guardrails.
- Validation & safety: Run output checks (types, policies, PII), add fallbacks/confirmations for risky actions, escalate to humans when uncertain.
- Memory & state: Short-term summaries for multi-turn tasks; long-term preferences stored with consent and retention rules.
- Observability & feedback: Logs, traces, evals, and A/B tests to measure accuracy, latency, cost, safety, and user satisfaction—and to improve over time.
How it comes together (example)
User asks, “Can I return order #123?”
The system retrieves the order, checks return policy and status, calls a policy tool, composes a response with the relevant snippet cited, offers a one-click RMA, records the action, summarizes the turn for memory, and flags edge cases for human review. The user sees one clean answer; behind the scenes, many components worked in concert.
Anti-patterns to avoid
- Prompt sprawl: Dozens of ad-hoc prompts with no shared structure.
- Context stuffing: Dumping everything into the window instead of retrieving the few, most relevant items.
- Tool bloat: Exposing too many tools without clear selection rules or safety checks.
Treat context engineering like product engineering: design the pipeline, instrument it, set SLAs (accuracy, latency, cost), and iterate. That’s the difference between a clever demo and a dependable system.
Why is Context Engineering Important?
Since so many LLM failures aren't "model problems"—they're context problems. When an agent responds incorrectly, hallucinates, or hesitates, it's often missing facts, lacks appropriate tools, or operates under imprecise constraints. Context engineering cures that by providing the appropriate information, unambiguous instructions, and controlled tool access at the right time, converting a smart demo into a reliable system.
Tangible benefits
- Reliability & accuracy: Fetch authoritative sources, anchor answers with citations, and use validation rules—radically lowering hallucinations and variance across runs.
- Consistency at scale: Packaged inputs (facts, policies, examples) into standardized packages make behavior deterministic across teams, products, and edge cases.
- Lower cost & latency: Fetch only what's relevant, short history summarization, and selective tool selection—eliminating tokens, retries, and escalations.
- Safety & compliance: Encode guardrails (PII handling, policy checks, permitted actions) and apply human-in-the-loop to high-risk actions.
- Observability & iteration: Log what was fetched, which tools executed, and why decisions were taken; then A/B test prompts, fetching strategies, and policies to learn over time.
- Business impact: Increased first-contact resolution, reduced manual handoffs, and the ability to automate more workflows with confidence.
What this looks like in practice
A support agent that used to guess at return policies now retrieves the exact policy, checks order status via API, drafts a response that cites the rule, and offers a one-click RMA—automatically escalating only when conditions aren’t met. Same model, different outcome, because the context is engineered.
In short, context engineering addresses the primary bottleneck in LLM applications: it gives models the facts, tools, and guardrails they need to be reliable, auditable, and production-ready.
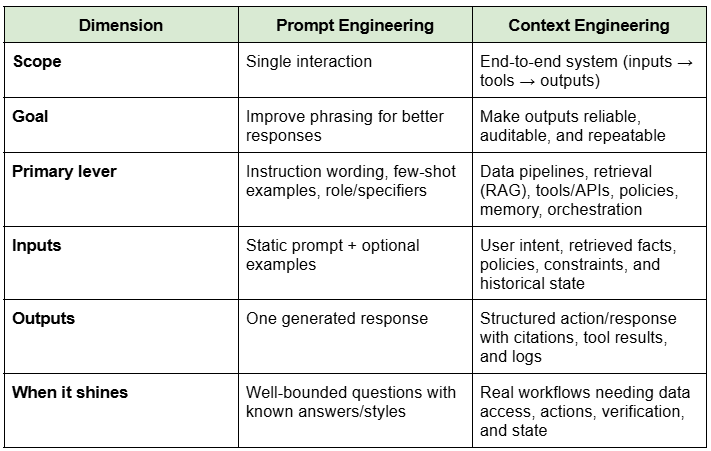
How is Context Engineering Different from Prompt Engineering?
Prompt engineering adjusts the wording of one instruction to receive an improved answer. Context engineering architected the system with respect to the model—how data is collected, formed, checked, and responded to—so good answers occur repeatedly, at scale. It's the difference between writing one ideal sentence and constructing the whole information pipeline that makes that sentence accurate, safe, and valuable within a product.
Examples of Context Engineering
Tool Use: Giving an agent a tool to search the web for the current weather before it answers a question about today’s forecast.
Short-Term Memory: Summarizing a long conversation so an agent can remember past interactions without having to process the entire chat history.
Long-Term Memory: Storing user preferences, like their favorite coffee order, and recalling it during a future conversation.
Information Retrieval: Fetching a specific document from a database and inserting its contents into the prompt so the LLM can answer a question about it.
Conclusion
As AI models get more sophisticated and autonomous, the context engineering emphasis will only increase. It's a paradigm shift, really, in how we construct LLMs—from focusing on fine-tuning the model itself to focusing on setting its world up for success. Tomorrow's strongest and most dependable applications won't be constructed on one clever prompt, but on the firm foundation of a well-designed context system. This is the ability that distinguishes an ordinary, passive bot from a genuinely intelligent and reliable agent.
SHARE THIS



Discover More Articles
Explore a curated collection of in-depth articles covering the latest advancements, insights, and trends in AI, MLOps, governance, and more. Stay informed with expert analyses, thought leadership, and actionable knowledge to drive innovation in your field.
.png)



Is Explainability critical for your AI solutions?
Schedule a demo with our team to understand how AryaXAI can make your mission-critical 'AI' acceptable and aligned with all your stakeholders.


AryaXAI provides the most accurate explainability and alignment stack to deliver accurate, true-to-model explainability, monitoring, risk management, and alignment techniques essential for highly mission-critical or regulated AI solutions.
Address: 3828 Kennett Pike, Suite 212 Greenville, DE 19807-2331
Products
Resources
Follow Us



Get in touch
.png)



