

Beyond Stateless Compute: Building Reliable Infrastructure for Intelligent Agents
8 minutes
September 4, 2025

AI apps are evolving from one-shot requests to goal-oriented agents that plan, use tools, collaborate with humans, and learn through experience. That transformation shatters many cozy assumptions in current stacks. Rather than brief, stateless requests, agents execute for hours or minutes, fork into concurrent subtasks, stream partial results, and pick up after interruptions or failures. They don't simply reply—they reason, act, remember, and learn—and that requires AI agent infrastructure designed specifically for these workloads.
Why does this need to matter now? The moment agents move outside of a chat window—scheduling shipments, reconciling invoices, routing tickets, tracking data pipelines—the operational costs increase. Naively gluing functions, queues, and cron jobs results in fragile systems: timeouts murder long tasks, retries redo work, state goes missing between steps, and LLM observability is guesswork. Reliability, safety, and cost control degrade.
This blog explores what it takes to run agents in AI production systems with confidence—highlighting where general-purpose compute falls short and the core runtime capabilities needed, such as durable execution, resumable state, and structured streaming. We’ll look at architecture patterns for orchestration, human-in-the-loop workflows, observability, and safety guardrails, along with strategies for performance, cost efficiency, and rollout. Finally, we’ll cover build-vs-buy considerations and share a practical checklist to help teams get production-ready.
1. Rethinking Architecture for Agentic Workloads
Most modern application architectures are optimized for short-lived, stateless interactions—think web requests or single API calls that start and finish within milliseconds. This model works well for traditional software but breaks down when applied to intelligent agents. Unlike a chatbot that responds once and resets, agents are designed to think, plan, and act over extended periods of time, often across multiple steps and systems.
Agents often run for extended periods, occasionally running for minutes or hours as they make outside calls to APIs, wait for user response, or execute sophisticated operations. In such cases, the infrastructure will need to be able to tolerate interruptions, save progress, and pick up where it left off without having to restart from the beginning. Stateless models such as standard serverless functions that run automatically for a predetermined timeout simply cannot accommodate this.
Also critical is state persistence. Agents must be able to recall context—historical user input, intermediate computations, recalled knowledge, and tool outputs. Without solid state management, agents can forget goals, repeat steps, or generate inconsistent outputs. For instance, an AI agent balancing books of accounts must maintain a working memory of processed transactions; resetting state in the middle of a task could result in error or duplication.
Agents also face spontaneous workload patterns. A single request from a user may branch out into numerous subtasks or invoke external workflows that cascade into sudden bursts of activity. Classic microservice designs—although scalable—usually depend on fixed orchestration and pre-defined service boundaries. Agents, however, need orchestration that can dynamically scale and evolve in accordance with spontaneous task trees.
When companies try to cram agentic workloads into serverless or microservice architectures, the outcome is usually instability: executions time out, state is lost from step to step, retries cause redundant work, and monitoring is opaque. These brittle systems might work at prototype scale but crumble when subjected to production loads.
Briefly, successfully implementing intelligent agents involves rethinking architecture at its foundation—away from short-running, stateless, request-driven designs toward long-running, stateful, robust AI agent infrastructure that can accept the complexity and dynamism of agent action.
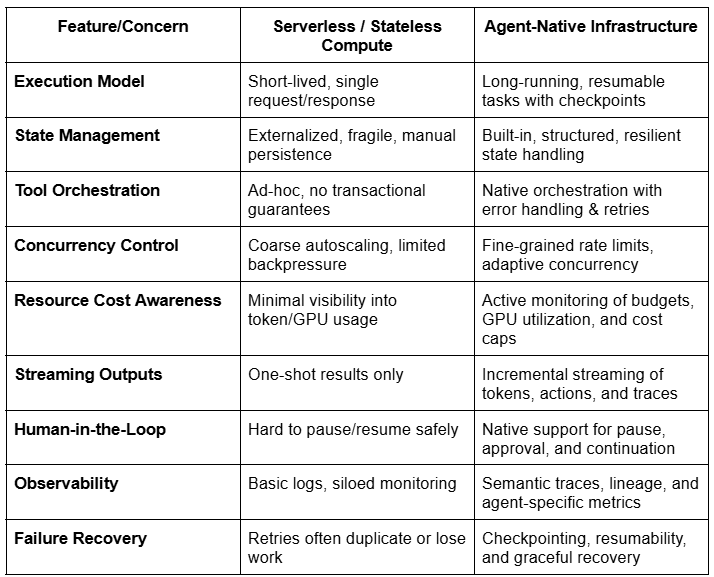
2. Why Standard Compute Falls Short
Most cloud stacks were designed around short, stateless requests: a web handler spins up, does a bit of work, and returns a response. That mental model is elegant—but it collapses when you introduce agents that plan, call tools, wait on humans, and run for minutes or hours. Here’s where the mismatch bites:
- Hard time limits and preemption. Functions-as-a-service and autoscaled pods assume quick completion. Long-running reasoning, multi-step workflows, or slow third-party APIs hit timeouts or get evicted mid-task, leaving half-finished work and no reliable way to resume.
- Ephemeral processes, fragile state. In stateless designs, anything you care about must be externalized—usually to a cache, queue, or database. Without first-class checkpointing and resumability, agents lose intermediate results, repeat steps, or fork into inconsistent states after retries.
- No built-in tool orchestration. Agents rely on external systems (search, databases, calendars, payment rails). Standard compute lacks transactional semantics across these calls. On failure, you get duplicated side effects, missing compensations, and tangled “saga” logic scattered across services.
- Coarse concurrency and missing backpressure. Queues and autoscalers can push more workers, but agents need fine-grained control: per-tool rate limits, adaptive concurrency (especially for LLM APIs), cancellation, and priority handling. Without it, you trigger thundering herds, API bans, and runaway costs.
- Resource cost management is missing. Unlike traditional apps, agents are heavily compute- and token-intensive. Infrastructure must actively manage token budgets, GPU utilization, and memory consumption to prevent runaway costs, inefficient GPU scheduling, and wasted cycles on repetitive or stalled tasks. Standard compute doesn’t provide this level of visibility or control.
- One-shot response channels, no streaming. Traditional request/response paths return only at completion. Agents benefit from structured streaming—partial tokens, tool traces, intermediate artifacts—so users and systems can observe progress, interject, or steer. Standard stacks rarely support multiplexed, typed streams out of the box.
- Human-in-the-loop is awkward. Approvals, disambiguation, or escalations require an agent to pause safely and resume later. Bolting this onto cron jobs or serverless flows invites race conditions, expired contexts, and brittle “sleep and poll” hacks.
- Opaque operations and weak observability. Logs smeared across services don’t capture agent reasoning, tool choices, or state mutations. Without semantic traces and step-level lineage, debugging becomes guesswork and regression testing is nearly impossible.
- Unbounded loops and cost drift. Stateless retries can hide infinite loops or degenerative planning. Absent guardrails like budget limits, retry policies, and safety checks, you risk silent burn and escalating bills.
The result: interruptions, lost progress, duplicated actions, and production incidents that are hard to reproduce. It’s not that serverless or microservices are “bad”—they’re just optimized for a different problem. Agentic workloads demand a runtime that treats durability, state, orchestration, streaming, scalability, and governance as first-class concerns rather than afterthoughts.
3. Core Requirements of Agent Infrastructure
3.1 Durable Execution
Intelligent agents often pause—to call out to external tools, await user validation, or adapt plans midstream. Effective infrastructure should:
- Run tasks outside of the original trigger context, continuing autonomously.
- Monitor health through heartbeat signals to prevent premature termination.
- Enable checkpointing and resumption so agents can recover gracefully after pauses or interruptions.
3.2 Robust State Management
Agents accumulate complex state: partial results, logs, contextual embeddings, and more. A foundational infrastructure must:
- Provide structured, reliable state persistence.
- Allow resumption, backtracking, or reconfiguration during mid-task lifecycles.
- Support human-in-the-loop operations, enabling agents to pause, await input, and continue seamlessly.
3.3 Scalable for Bursts
Real-world agents must tolerate surges—from sudden user demand spikes to scheduled batch operations. Key infrastructure capabilities include:
- Intelligent task queues to buffer and orchestrate workload spikes.
- Horizontal scaling that dynamically points new workers to incoming tasks, ensuring reliability under load.
3.4 Real-Time Transparency via Streaming
Modern agents are dynamic thinkers, not black boxes. Infrastructure should:
- Offer live, incremental streaming of outputs—tokens, thoughts, tool actions—back to users or monitoring systems.
- Support flexible, structured data streams (not just plain text), facilitating richer interfaces and better traceability.
- Retain metadata context to trace output origins and simplify debugging.

4. Empowering Developers to Focus on Logic
When the runtime manages durability, state, autoscaling, observability, and human-in-the-loop breakpoints, engineers cease babysitting infrastructure and begin crafting intelligence. The center of gravity shifts from wiring queues and retries to responding to more valuable questions: What does the agent attempt? How does it determine that? When should it be requested by a human? What "good" is production? This is how that payoff works:
- Shorter iteration loops. With resilient execution and restartable state, you can re-play traces deterministically, interchange prompts or policies, and re-execute only the one failed step rather than a full flow. That translates into quicker "edit → run → examine → improve" cycles.
- Less glue code, more reusable patterns. Tool schemas, selection policies, and planning strategies, which are defined once by developers, replace tailored orchestration. Agents use these abstractions in a standardized format without re-implementing queues, locks, or compensations.
- Better debugging through semantic traces. Step-level checkpoints and structured streaming make the why of what you're doing—plans, tool calls, intermediate results—available so that you can compare two runs, time-travel to any checkpoint, and detect flakiness without grepping logs across services.
- Safety by construction. Guardrails (budgets, rate limits, RBAC, allow/deny lists, data redaction) are enforced at the platform, not sprinkled across app code. Developers specify policies ("human approval required prior to payments," "limit tool cost to $X"), and the runtime enforces them.
- Operational confidence out of the box. Integrated SLOs, idempotent retries, circuit breakers, and backpressure ensure agents stay healthy under load. Feature flags and canary releases enable you to release new behaviors incrementally, then roll back safely if metrics deteriorate.
- Separation of concerns that supports scaling teams.
- Platform does the runtime (durability, state, streaming, HITL, observability).
- App/ML teams have the cognitive layer (planning, tooling choice, prompting, memory strategy).
- Ops/Compliance establish policies and review loops.
- This transparency simplifies handoffs and speeds delivery.
A brief example: A billing-reconciliation agent has to gather invoices, match them against ledgers, work through mismatches, and get approvals. Using an agent-native platform, developers concentrate on matching heuristics, escalation rules, and tool schemas. The runtime takes care of long API waits, batch checkpoints, streaming progress to reviewers, waiting for sign-off, and resuming safely—no custom cron ballet or ad-hoc retry spaghetti.
Conclusion
The rise of autonomous, goal-driven agents marks a shift in how we design software. Stateless compute isn’t enough—teams need AI agent infrastructure purpose-built for long-running tasks, stateful execution, and adaptive scalability. By adopting platforms that deliver durable execution, robust state, real-time transparency, and cost controls, organizations can move beyond fragile prototypes and build production-ready AI systems.
This evolution doesn’t just make agents reliable—it empowers developers, strengthens governance, and ensures users experience agents that are trustworthy, efficient, and effective. By prioritizing infrastructure tailored for AI production systems, businesses lay the foundation for intelligent applications that scale with confidence.
SHARE THIS



Discover More Articles
Explore a curated collection of in-depth articles covering the latest advancements, insights, and trends in AI, MLOps, governance, and more. Stay informed with expert analyses, thought leadership, and actionable knowledge to drive innovation in your field.
.png)



Is Explainability critical for your AI solutions?
Schedule a demo with our team to understand how AryaXAI can make your mission-critical 'AI' acceptable and aligned with all your stakeholders.


AryaXAI provides the most accurate explainability and alignment stack to deliver accurate, true-to-model explainability, monitoring, risk management, and alignment techniques essential for highly mission-critical or regulated AI solutions.
Address: 3828 Kennett Pike, Suite 212 Greenville, DE 19807-2331
Products
Resources
Follow Us



Get in touch




